
Markus Kraft is a Professor at the University of Cambridge, UK, and Director of CARES, the Cambridge Centre for Advanced Research and Education in Singapore. Part of his research work is “The World Avatar (TWA) project”, which explores creating an interconnected network of digital twins that can describe the behavior of any complex system. This could enable data-driven decisions to optimize all systems, which could be used to create chemical knowledge, laboratory automation, smart city operations, climate resilience, and national energy scenarios, among other applications.
Here, he talks with Vera Koester for ChemistryViews about his World Avatar project, what knowledge engineering and machine learning are, their applications in chemistry, and the biggest challenges and successes in using AI.
What is knowledge engineering (KE)?
Knowledge engineering is a branch of artificial intelligence (AI) that mimics the decision-making process of a human expert. KE has a long history. In the early 1980s, computer scientists developed what they called expert systems. These contained a database and a rule book and could provide answers to particular questions. However, these systems fell out of favor because the data was only on a local computer, and you couldn’t easily connect it to other computers.
But in 2001, Tim Berners-Lee, the inventor of the World Wide Web, published an article in Scientific American magazine about the Semantic Web [1]. The Semantic Web is basically the internet as we know it, but with annotated websites so that their contents are understandable to machines. It provides a digital platform to interconnect machines and autonomous software programs (i.e., agents). The Semantic Web was always incredibly exciting for knowledge engineers worldwide, as it can interconnect heterogeneous data and diverse knowledge expert systems into “ecosystems of knowledge”.
What are the basic principles or what kind of data structure does KE rely on?
We don’t build these ecosystems of knowledge using relational data structures (i.e., tables) but with graph representations. All data or information is represented as individual nodes and interconnected through edges that stipulate their relationship (see Fig. 1). Consequently, these ecosystems of knowledge came to be called knowledge graphs.
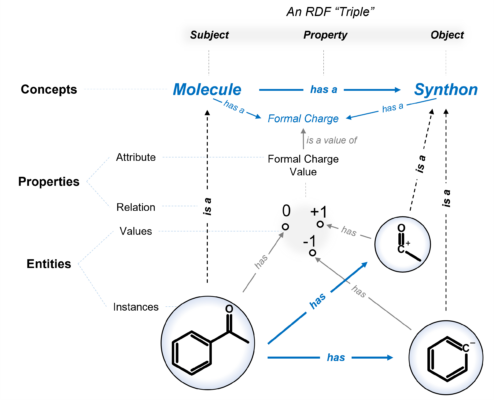
Figure 1. Mapping the relationship between molecule and synthon concepts and illustrating them with instances. Description of an RDF triple (top) and ontology stacking (left).
A knowledge graph is a way to organize complex information and relationships. Typically, knowledge graphs are structured through ontologies. An ontology (a map of concepts that helps to organize the information) is a very specific knowledge representation used for the internet, basically a standard. One can consider it as a blueprint, schema, or map of concepts that models a particular known domain. All data and information that make up the knowledge graph are instantiated (making a copy of a blueprint or template to create a specific object or instance) based on the designed ontology.
So now one of the limitations of expert systems have been overcome by the internet, which has enabled linked open data, which is being increasingly used in various fields. Biologists were the first to use this type of representation and have had enormous success in representing DNA and proteomics. Also Wiki data is now structured as a knowledge graph. So suddenly you have knowledge information represented not just as written information, like in Wikipedia, but also as internal knowledge on the internet, allowing data to identify itself. This will hopefully help in creating or doing knowledge engineering in the field of chemistry or in any other area.
What kind of problems do you solve with KE?
We don’t restrict ourselves to a specific problem, but before I go into this very general view, I can give you a few examples: Knowledge engineering may help you find reactants, possibly catalysts, that produce better yields or fewer by-products. Or knowledge engineering may help you run a lab. Knowledge engineering may help you develop a combustion model for a particular fuel. Knowledge engineering may help you organize your chemical components in the lab and help you fill out the safety forms. These are just a few examples.
Chemists initially used knowledge engineering to automate mass spectrometric analysis and retrosynthesis. DENDRAL (of the 1960s) and LHASA (of the 70s) are the two most famous legacy knowledge systems used in mass spectrometry and toxicology. They were the blueprint for designing other knowledge systems for chemistry. Knowledge systems can also be involved in the backend of many applications. For example, they may provide direct interpretation of peak assignments or carry complex questions and operations.
Today, such systems can ensure different lines of research are completely interoperable, allowing electronic lab notebooks to represent and capitalize on data from various sources (e.g., instruments, experiments, calculations, etc.).
How is this connected to one of the other well-known terms: machine learning (ML)?
Machine learning is a form of artificial intelligence that allows computers to learn from data and improve their performance on a specific task over time, without being explicitly programmed. By setting up a mathematical modelinspired by neural networks, similar to the structure of our brain. Machine learning algorithms use statistical models to analyze and learn from patterns in data instead of following a fixed set of rules. They then use the knowledge gained from this analysis to make predictions or decisions.
I can’t talk about this topic without mentioning my superhero Marvin Minsky, one of the founders who coined the term AI, artificial intelligence, and was a Professor at MIT. He wrote theoretical papers suggesting that a one-layer neural network won’t be able to do cognitive tasks. This limitation hindered the development of neural networks for decades.
However, the emergence of multi-layer neural networks around 15 years ago changed this. Very recently, there was a breakthrough paper with the fantastic title “Attention is all you need” [2]. This led to transformer networks which built the basis for technologies like GPT3, ChatGPT, or Google Bard.
These big language models are essentially sequence models. That means that there is a given sequence, and they can predict what’s the next thing to come but this is purely data-driven. Meaning they don’t really know what the next thing to come will be, they just tell you in terms of probability based on very clever statistics.
In machine learning, does that mean that the way I train the system makes it better, or the algorithm I use for the system?
The algorithm is basically part of the training, it’s this transformer network. But, of course, it makes a big difference if you have many layers in the deep neural network, that give you parameters, and if the data that you train the whole model with is very large. This is a very expensive process. No university could ever do this. Partly because they don’t have the data and partly because they don’t have the computer power to do it. It really needs big players.
What are the advantages of using KE in chemistry applications over ML?
In our view, knowledge engineering has an advantage over machine learning in two ways:
- When the outcome must be explainable.
- When data is scarce.
The first scenario would be for operations or results propagating across multiple domains (e.g., digital drug design) and scales (e.g., from combustion to soot formation). In these situations, chemists want to know and understand why they get a particular result at a specific stage, as in many cases being just statistically significant may not be helpful.
For the second scenario, as mentioned before, many chemical domains are small communities that use modest amounts of data that may not be attractive to machine learning projects. Hence, they risk being left behind regarding digital transformation. KE offers such communities and domains the opportunity to benefit from AI.
What’s the big advantage of using both knowledge engineering and machine learning together?
Some of my team members are working on this right now. It turns out that these machine learning algorithms are super effective—they’re fast. For example, if we Google something, we get an answer immediately. In contrast, semantic techniques with knowledge graphs know what things are, but they are often slow. But if you use these semantic networks as training material, you can embed the knowledge graph, and therefore the knowledge that is in the graph, into the machine learning model. In this way, one gets the advantages of both sides.
This will completely revolutionize everything. If some people think that ChatGPT is the end of development, I can assure them, it is just the start. There is a tsunami of innovations coming. This will have a massive impact on chemistry, but not just chemistry, everything.
How far has research gone? Where are such KE technologies currently adopted?
Research on knowledge engineering technologies has come a long way in our group, with significant developments on various scales. For example, we have created ontologies to link concepts from the molecular level up to the building level. Using these ontologies, we have constructed digital twins of laboratories, including all the chemicals and hardware. Additionally, we have developed autonomous agents to manage lab operations, from designing and executing experiments to analyzing results in a closed loop until we achieve the research goals set by scientists. We have also integrated with building management systems, providing researchers with comprehensive and contextual information about the reactions taking place in real-time.
For example, research scientists conducting experiments and lab managers taking care of operations usually have very different expertise and even conflicting goals. With our knowledge engineering approach, an autonomous agent suggesting the next step has access to vast chemical data (to maximise the yield) but also knows about inventory and assets (to check if required chemicals and devices are even available) and even energy costs (electricity for devices and air conditioning) which might vary based on weather and market conditions. While the adoption of these KE technologies is still relatively limited, we see a huge potential for them in various contexts, including academic research and industrial applications.
So does a chemist still need to have a sound knowledge of chemistry, or is that becoming less important because the system has that knowledge?
For now, chemists still need knowledge of chemistry, but very soon they won’t.
Since chemistry is beautiful, one may still wish to read chemistry textbooks in the near future, but whether you will need that knowledge to find a new material or synthesize a new molecule—I doubt it—because soon overall knowledge creation will be fully automated.
That’s my personal opinion, and given that I’m a science fiction enthusiast, maybe I’m a little too optimistic about the development of knowledge engineering in chemistry. But I can see the progress in our lab, what we have achieved already this year, and what we will have achieved by the end of this year.
Hearing your answer, I think that maybe the person working with these systems, training them, must be a better chemist than the person using them to find a better catalyst or material.
Human expertise and creativity are still essential in designing, implementing, and interpreting chemical research and development. Intelligent systems are only as good as the data and algorithms they are trained on, and human experts are needed to ensure the accuracy and reliability of these systems. As such, humans will continue to play a role in chemistry and chemical engineering, even as intelligent machines become more advanced.
All the intellectual ambitions of humans will not vanish. On the contrary, with such a system, you can reach completely new heights.
What is The World Avatar (TWA) you are working on? What will it be used for in chemistry?
The World Avatar project is a knowledge-graph-based world model that pursues the idea of mapping every aspect of the real world into a digital “avatar” world. The idea is to create digital twins that can describe the behavior of any complex system, thereby providing the ability to make data-driven decisions about how to optimize all of them. You can also refer to TWA as an eco-system of connected digital twins (cTW).
![]()
Figure 2. Three layers of the World Avatar (TWA).
To support research in chemistry, we have developed a series of ontologies that cover various chemistry domains, such as chemical species, kinetic mechanisms, computational chemistry, physical experimentation, and chemistry laboratories. Using TWA, we have for example, successfully simulated the effects of quantum calculations on the atmospheric dispersion of pollutants in Singapore, performed automated kinetic mechanism calibrations, and enabled the automated rational design of metal-organic polyhedra (MOPs)—we have a nice paper in JACS on that [3]. Other aspects include laboratory automation, building management, smart city operations, climate resilience, and national energy scenarios. You can see many different applications all within the umbrella of The World Avatar on my group’s website.
Additionally, we have developed a natural language processing system to improve accessibility for researchers to interact with their data. We aim to provide a more connected and accessible laboratory environment for researchers.
What are the biggest challenges at the moment?
Clearly, I cannot do this on my own. KE applications require a significant investment of time, resources, and a team of highly skilled and specialized researchers and engineers. One of our primary challenges is building and maintaining a talented team with expertise in different domains. This can be particularly challenging as we are at the cutting edge of interdisciplinary fields such as chemistry, chemical engineering, and computer science, and given that the university education doesn’t deliver that, it’s a million miles away from this. So, staying ahead of the competition and continuously improving the technology is crucial for us to attract the best people. After a few years, I have now developed a wonderful team and if you ask me what I enjoy most, it is working with these fantastic people. This is super inspiring.
Another challenge for us is to build and implement rigorous development practices throughout the project. This is especially important as we are developing artificial intelligence that operates autonomously in the laboratory. This can have real-world consequences. Therefore, we take extra care to ensure that the technology is developed responsibly and ethically.
Do you sometimes worry that these systems, for example, The World Avatar, might be misused?
That’s why I think so much about goals. If you build such a system, you have great promise but also great danger. In the artificial intelligence literature, it is called goal alignment. If we build such a strong and capable system, then we must make sure that the goal of the system aligns with benign human goals. I’m very much interested in a world where we can live in peace and a world that respects our environment, basically a sustainable world. If you want to read more about this, my colleague Oliver Inderwildi and I just edited a book [4], that has a chapter on goal alignment and the potential dangers of AI.
The question is: How can we avoid such a system going wrong? How do you get AI to be friendly? These are really important questions, and that’s why we turned to the UN, among others, to align with their Sustainable Development Goals.
If everything is connected, then no matter what you do it will have a multitude of effects. Not all these effects are good; you cannot live in a perfect world. The philosopher and mathematician Gottfried Wilhelm Leibniz claimed that we live in the best of all thinkable worlds. But, of course, this means the best possible world for everyone. That also means that there will always be a compromise, or we mathematicians would say this is in a Pareto space. In this large space of all possible outcomes, there is a small subspace that is good enough.
The Word Avatar will offer an opportunity to investigate these compromises. This is why this is so exciting and potentially lifesaving.
What would you advise young people to learn so that they are well-prepared for the future?
I would say pure mathematics … [laughs]
I don’t think there is a right answer to this question. I think the most important thing in a future with the World Avatar and superintelligence is to follow your own instincts—whatever gets you going. If you like certain aspects of chemistry and maybe you find molecules beautiful, then that’s what you must do. If you think the underlying theory, quantum chemistry or quantum computing is great, then go and do that.
Can you please say a few words about the CARES lab?
The CARES lab was established ten years ago and has a very large research stream called the Cambridge Centre for Carbon Reduction in Chemical Technology (C4T). We are looking at different technologies or techniques used to reduce atmospheric CO2 levels. One of the aspects is chemical reaction engineering, for example, for carbon capture and isolation of CO2 streams using looping techniques. Then we use a lot of electrochemical carbon utilization, for example, a CO2 gas diffusion electrode to convert CO2 to hydrocarbons. We just published an article on this in Energy & Environmental Science [5].
Another research strand deals with fuels, in particular, the emissions from carbon-neutral fuels, i.e., biofuels. We are also doing flame synthesis of catalytic processes, and we have made titanium dioxide particles decorated with platinum for photocatalytic water splitting. And finally, we have a major research focus in classical systems engineering, which has led to the development of the World Avatar, the world model that I just talked about. This model was basically motivated by the interconnection of plants in an industrial park. We are also looking at the economics of the chemical industry, which would lead to different ways of producing some chemical products that would save us fossil fuels.
Apart from this big proposal, we also have smaller proposals, for example on the science of learning. That is completely disconnected from the engineering branch. In the future, we are planning to investigate public health.
We are working on projects with our sister universities, which are the National University of Singapore (NUS) and the Nanyang Technological University (NTU). We are based at Singapore’s Campus for Research Excellence and Technological Enterprise (CREATE). The whole building is like a catalytic surface where academics from all over the world combine, e.g., from the University of Cambridge, the Massachusetts Institute of Technology (MIT), the University of California (UC) Berkeley, the Technical University of Munich (TUM), ETH Zurich, and more. It’s unique in the world and I’m very happy that I can be here. All the work I’ve been talking about is only possible because I’ve been working with very, very good students and postdocs and I’m very grateful for this. That is the best part of my scientific existence—to be able to work with such gifted people.
Yeah, it sounds like you’re kind of inside the melting pot of our future.
I personally believe that the changes that are coming are enormous and that they’re much faster than we think. As I said, ChatGPT is just the beginning.
I think we should be careful. I’m very excited to be part of the process because I think we can learn a lot about ourselves and we can learn a lot about chemistry. I have been learning a lot about chemistry because at the moment these knowledge models are not completely automated, they are made by hand, and together with my postdoc Aleksandar Kondinski, we’ve been exploring this space. It’s been a real adventure learning more and more about it and so I hope that many people share our enthusiasm. At this point, I would like to say that I met Aleksandar through the Humboldt Foundation, from which I have greatly benefited in the past, and I am very grateful to them.
Thank you very much for this fascinating insight into the future.
References
[1] Tim Berners-Lee, James Hendler, Ora Lassila, Semantic Web, A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities, Scientific American May 2001.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, Attention Is All You Need, arXiv 2017. https://doi.org/10.48550/arXiv.1706.03762
[3] Aleksandar Kondinski, Angiras Menon, Daniel Nurkowski, Feroz Farazi, Sebastian Mosbach, Jethro Akroyd, Markus Kraft, Automated Rational Design of Metal−Organic Polyhedra, J. Am. Chem. Soc. 2022, 144, 11713−11728. https://doi.org/10.1021/jacs.2c03402
[4] Intelligent Decarbonisation, Can Artificial Intelligence and Cyber-Physical Systems Help Achieve Climate Mitigation Targets? (Editors: Oliver Inderwildi, Markus Kraft), Springer, Heidelberg, Germany, 2022.
[5] Simon D. Rihm, Mikhail K. Kovalev, Alexei A. Lapkin, Joel W. Ager, Markus Kraft, On the role of C4 and C5 products in electrochemical CO2 reduction via copper-based catalysts, Energy Environ. Sci. 2023, 16, 1697-1710. https://doi.org/10.1039/D2EE03752A
Markus Kraft studied mathematics, physics, and computer science and received his Diplom-Technomathematiker degree from the University of Kaiserslautern, Germany, in 1992 and his Ph.D. in technical chemistry from the same university in 1997. He then worked at the University of Karlsruhe, Germany, and the Weierstrass Institute for Applied Analysis and Stochastics in Berlin, Germany. In 1999, he became a Lecturer at the University of Cambridge, UK. Currently, Markus Kraft is a Professor there in the Department of Chemical Engineering and Biotechnology and Director of CARES Ltd, the Cambridge Centre for Advanced Research and Education in Singapore. He is also a Principal Investigator for the Cambridge Centre for Carbon Reduction in Chemical Technology (C4T) and leads the Computational Modeling Group (CoMO) in Cambridge.
Markus Kraft’s research includes computational modeling and optimization for the development of carbon reduction and emission abatement technologies for the automotive, energy and chemical industries, understanding combustion synthesis of organic and inorganic nanoparticles, and engine simulation, spray drying and fine powder granulation. More recently, he has been working on digitalization, in particular knowledge graphs.
Selected Awards
- Fellow of the Alan Turing Institute, elected 2021
- Fellow of the Combustion Institute, elected 2020
- Fellow of IChemE, 2018
- Friedrich Wilhelm Bessel-Forschungspreis, 2016
- DFG Mercator Fellow, 2012
- Beilby Medal, RSC, 2006
Selected Publications
Aleksandar Kondinski, Jiaru Bai, Sebastian Mosbach, Jethro Akroyd, Markus Kraft, Knowledge Engineering in Chemistry: From Expert Systems to Agents of Creation, Acc. Chem. Res. 2022, 56, 128–139. https://doi.org/10.1021/acs.accounts.2c00617
Mei Qi Lim, Xiaonan Wang, Oliver Inderwildi, Markus Kraft, The World Avatar – a World Model for Facilitating Interoperability, Technical Report 277, c4e-Preprint Series, Cambridge, 2021.
Jiaru Bai, Liwei Cao, Sebastian Mosbach, Jethro Akroyd, Alexei A. Lapkin, Markus Kraft, From Platform to Knowledge Graph: Evolution of Laboratory Automation, JACS Au 2022, 2, 292–309. https://doi.org/10.1021/jacsau.1c00438
Xiaochi Zhou, Daniel Nurkowski, Sebastian Mosbach, Jethro Akroyd, Markus Kraft, Question Answering System for Chemistry, J. Chem. Inf. Model. 2021, 61, 3868–3880. https://doi.org/10.1021/acs.jcim.1c00275
Jiaru Bai, Rory Geeson, Feroz Farazi, Sebastian Mosbach, Jethro Akroyd, Eric J. Bringley, Markus Kraft, Automated Calibration of a Poly(oxymethylene) Dimethyl Ether Oxidation Mechanism Using the Knowledge Graph Technology,
J. Chem. Inf. Model. 2021, 61, 1701–1717. https://doi.org/10.1021/acs.jcim.0c01322
Jethro Akroyd, Sebastian Mosbach, Amit Bhave, Markus Kraft, Universal Digital Twin – A Dynamic Knowledge Graph, Data-Centric Eng. 2021. https://doi.org/10.1017/dce.2021.10
Feroz Farazi, Maurin Salamanca, Sebastian Mosbach, Jethro Akroyd, Andreas Eibeck, Leonardus Kevin Aditya, Arkadiusz Chadzynski, Kang Pan, Xiaochi Zhou, Shaocong Zhang, Mei Qi Lim, Markus Kraft, Knowledge Graph Approach to Combustion Chemistry and Interoperability, ACS Omega 2020, 5, 18342–18348. https://doi.org/10.1021/acsomega.0c02055
Markus Kraft, Andreas Eibeck, J‐Park Simulator: Wissensgraph für Industrie 4.0, Chem. Ing. Tech. 2020, 92, 967–977. https://doi.org/10.1002/cite.202000002
Oliver Inderwildi, Chuan Zhang, Xiaonan Wang, Markus Kraft, The impact of intelligent cyber-physical systems on the decarbonization of energy, Energy Environ. Sci. 2020, 13, 744–771. https://doi.org/10.1039/C9EE01919G
Angiras Menon, Nenad B. Krdzavac, Markus Kraft, From database to knowledge graph — using data in chemistry, Curr. Opin. Chem. Eng. 2019, 26, 33–37. https://doi.org/10.1016/j.coche.2019.08.004
Also of Interest

Discussing science communication, AI in chemistry, publication ethics, and the purpose of life with an AI

Alexei Lapkin, University of Cambridge, UK, on the state of the art and challenges of transforming chemistry into the digital realm

Collection: Fascinating Insights into AI and Chemistry
An expanding compilation of articles concerning the intersection of artificial intelligence and chemistry
![]()

