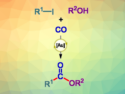
The Suzuki–Miyaura reaction is widely used to form new C–C bonds in organic chemistry. Such reactions that combine two fragments can be employed in automated syntheses to generate a wide range of products from a library of different building blocks. For such automated syntheses, reaction conditions that are general, i.e., applicable to a wide range of substrates and high-yielding, are useful. However, optimizing the reaction conditions is challenging due to the very large “search space” of possible substrate combinations and conditions. Existing research often does not include negative results, which limits the available data and further hinders the search.
Bartosz A. Grzybowski, Allchemy, Inc., Highland, IN, USA, Institute of Organic Chemistry, Polish Academy of Sciences, Warsaw, Poland, Institute for Basic Science and Ulsan Institute of Science and Technology, Ulsan, Republic of Korea, Martin D. Burke, University of Illinois at Urbana-Champaign, USA, and colleagues have performed an optimization of general reaction conditions for the heteroaryl Suzuki-Miyaura coupling. The team used a closed-loop workflow to efficiently navigate the large search space.
First, the researchers strategically reduced the matrices of possible substrate combinations and possible reaction conditions in such a way that they remained representative. They were left with a set of eleven representative substrate pairs that maximize the diversity of the resulting products. The possible reaction conditions were similarly reduced to three dissimilar solvents, two different bases, seven catalyst systems, and two different temperatures.
The team then performed an initial set of coupling reactions using automated synthesis with a robotic system. Starting from the results of these reactions, machine learning was used to optimize the conditions to give the highest average yield across the widest range of chemical space possible. Based on the available data, the machine learning model was improved, followed by a new round of automated experiments to yield new data. After five closed-loop rounds, the model converged and the optimization was stopped. The optimized conditions provide 72 % average yield across all included substrates, an improvement over previous benchmark conditions.
The researcher’s approach generates data that reflects both positive and negative results during optimization, which improves the accuracy of its predictions. According to the team, the developed workflow could also be applicable to other reactions.
- Closed-loop optimization of general reaction conditions for heteroaryl Suzuki-Miyaura coupling,
Nicholas H. Angello, Vandana Rathore, Wiktor Beker, Agnieszka Wołos, Edward R. Jira, Rafał Roszak, Tony C. Wu, Charles M. Schroeder, Alán Aspuru-Guzik, Bartosz A. Grzybowski, Martin D. Burke,
Science 2022, 378, 399.
https://doi.org/10.1126/science.adc8743
![]()