
Persistent Identifier
A persistent identifier (PID) is a long-lasting reference to an object or information. PIDs are important for a robust, trusted, and open research information infrastructure. The DOI, or Digital Object Identifier, is an example of a PID which we have known for many years. The DOI is a unique and easy identification code for research output such as journal articles.
The ORCID, the Open Researcher and Contributor iD, distinguishes one researcher from every other researcher and keeps track of their publications no matter if a researcher’s affiliation or field of research changes, if their name changes, if others have the same name, or if their name is translated into other alphabets, or is listed differently in different systems. ORCID was launched in October 2012.
And now, ROR, the Research Organization Registry, is added as an equivalent for research organizations. It provides an open and community-driven solution to the challenge of how to identify organizations in affiliations in the research and publishing process. So far, this kind of information was collected in a variety of ways mainly by commercial products. ROR is intended to enable more efficient discovery and tracking of research outputs across institutions and funding bodies. The ROR minimum viable registry (MVR) was launched in January 2019.
What is ROR?
ROR is a community-led project. In an initial process, a joint vision was developed by many different stakeholders of the research community including research organizations, librarians, platform providers, metadata services, research offices, publishers, and funders. ROR was launched and is currently organized by four organizations, Crossref, California Digital Library, DataCite, and Digital Science, and lead by a steering group. In addition, there is a community advisory group of more than 40 volunteers from across the research sector.
The ROR project team wants to develop a service that the community finds helpful. “ROR should be the open, sustainable, usable, and unique identifier for every research organization in the world.” Research organization is defined as any organization that conducts, produces, manages, or touches research, such as universities, institutes, societies, companies, publishers, or funding organizations. ROR should enable as many connections as possible between organization records across systems. It should not duplicative existing structures.
Currently, unique ROR IDs exist for about 97,000 organizations. The ROR registry was launched with seed data from Digital Science’s Global Research Identifier Database (GRID) database of organizations. This allowed ROR kind of a jump start in launching the registry instead of having to filter and collect all data from scratch. Digital Science is not interested in managing the whole community engagement aspect around the registry. Ultimately the two registries will diverge. But right now, the two registries are still very closely aligned in the sense that they are still setting up the technologies and processes within ROR to be able to carry all the records independently.
Benefits
“ROR data will be used by and useful for anyone who needs to track or collect institutional research output including research administration, policy administration, funders, librarians, institutional repositories.”, the ROR team says. “Librarians and academic administrators, for example, increasingly need access to data on their institutions’ publications and research outputs to support reporting requirements, funder and government mandates, institutional open access policies, and library collection development and licensing negotiations.”
Very important to them is that:
- ROR is community-driven: No single organization should own ROR.
- ROR is open: ROR data is CC0 and will always be free and open for all.
- ROR focusses specifically on the affiliation use case; it focusses on capturing and identifying which organizations are associated with which research outputs. It is not meant to be a comprehensive registry of all legal entities in the world.
- ROR provides an open and usable registry for top-level research organizations.
How Does ROR Work?
From the outside, ROR is not as visible as the DOI with its “https://doi.org”-link being displayed and the ORCID with its characteristic logo ![]() . It is not directly visible which affiliations are sourced from ROR and which are connected to a ROR ID. This might, however, change in the future. A logo similar to the ORCID logo connected with a link might be possible.
. It is not directly visible which affiliations are sourced from ROR and which are connected to a ROR ID. This might, however, change in the future. A logo similar to the ORCID logo connected with a link might be possible.
How does ROR actually work? For the user who is asked to give their organization’s name instead of a free text field that allows multiple ways of writing the same organization, a dropdown menu or affiliation matching functionality connects the entry in the background to the ROR API.
ROR records include metadata such as the organization’s name, alternative names, the organization’s location, and URL. ROR can support multiple languages and character sets such as Japanese, Chinese, Korean. All ROR IDs and metadata are under the Creative Commons CC0 1.0 Universal Public Domain Dedication. This means the data is dedicated to the public domain.
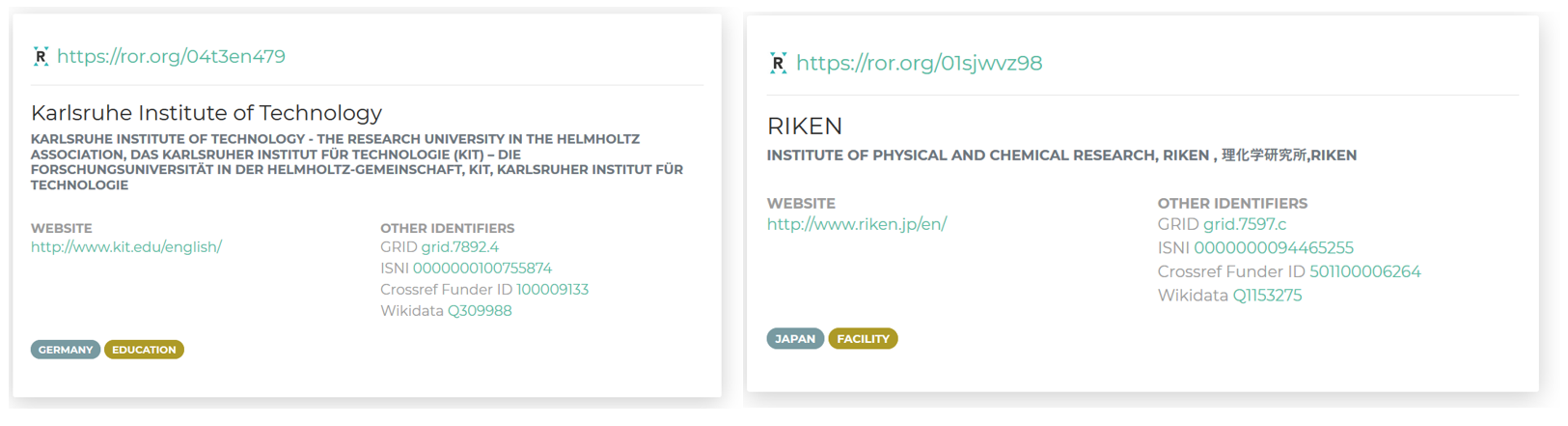
Figure 1. Examples of ROR entries for KIT in Germany, and Riken in Japan.
ROR is interoperable with other identifiers. ROR IDs map to GRID, ISNI, Crossref Funder ID, and Wikidata (see also Fig. 1).
Outlook
The ROR project team envisions that ROR will be integrated into all layers of the scholarly communication landscape in the next five years, including repositories, manuscript tracking systems, funder platforms, etc. Driving adoption is a current goal.
Future goals include adding additional metadata to ROR such as cities, and related records, and to have ROR IDs supported in Crossref and DataCite metadata schemas. Crossref is working on their metadata update, the ROR team told ChemistryViews. This will make it possible to run queries on how many articles come from one university, for example.
So far, all work has been completed through donations from ROR steering organizations. To scale up operations, hire dedicated staff, and develop and deliver new features, a fundraising campaign is running.
- ROR
- Are you Ready to ROR? An Inside Look at this New Organization Identifier Registry,
Alice Meadows,
The Scholarly Kitchen, Dec 4, 2019.
![]()



