Our genome is a chemical text written in our DNA using four letters. According to the blueprints it contains, thousands of different proteins are built from 20 amino acids in the cells of all living beings. The mechanism by which this four-letter DNA is transformed into a twenty-letter amino acid text is known as the genetic code.
Many brilliant minds worked on deciphering this code, and the goal was thought to have been achieved over sixty years ago: Crick, Griffith, and Orgel published a code so captivatingly beautiful that it simply must have been right [1–3]. After a few years, a relatively simple experiment proved that nature, unfortunately, does not use this brilliant code, preferring to take less elegant routes of its own.
Let’s take a closer look at this seeming chemical irrationality of nature.
1. Francis Crick and James Watson’s DNA Double Helix
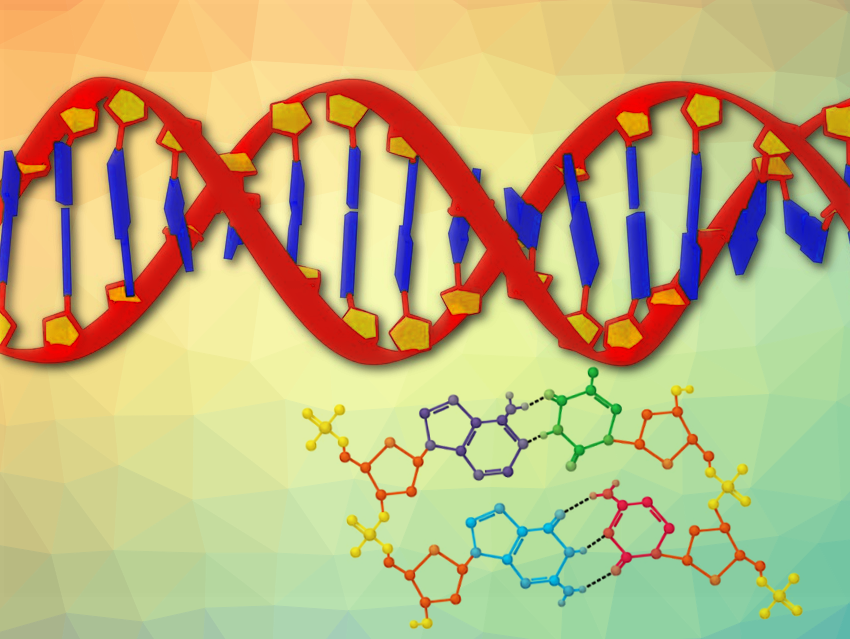
Based on X-ray crystallographic experiments carried out by Rosalind Franklin and Maurice Wilkins, James Watson and Francis Crick pulled off a scientific masterpiece with their determination of the structure of DNA in 1953 [4]: Two strands of DNA wind together to form a double helix. Even a fleeting glimpse at the structure of the DNA double helix (see Fig. 1) reveals the doubling step that forms the basis of heredity: The two complementary single strands are separated, and each receives a new complement. The resulting publication by Francis Crick and James Watson in the journal Nature [5] radiates a certain finality because it proves the molecular basis for heredity once and for all, “…the precise sequence of the bases is the code which carries the genetical information” [6].
 |
|
Figure 1. The DNA double helix. |
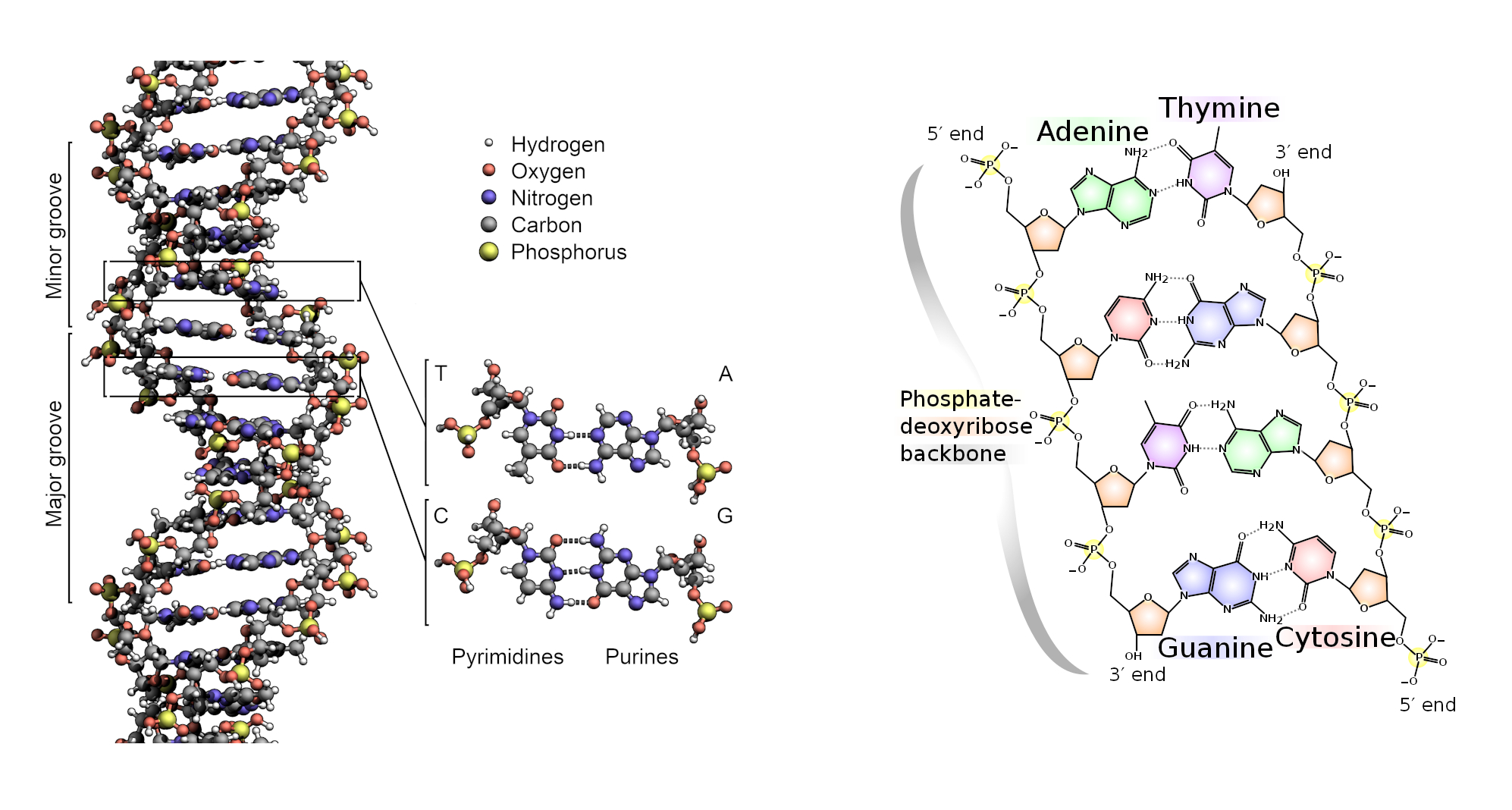
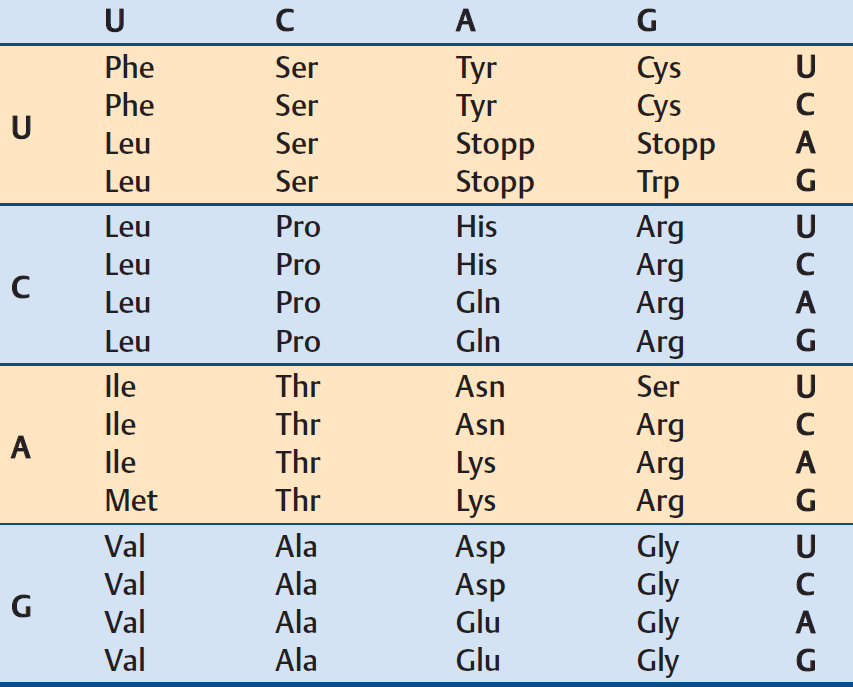
 But the nature of the genetic code, by which about 20 amino acids are coded in DNA with four building blocks, remained a complete mystery. Today, the genetic code can be found in tables in any biochemistry textbook (see Tab. 1), including the chemical details of the information transfer from DNA through RNA to the protein (see Infobox 1).
But the nature of the genetic code, by which about 20 amino acids are coded in DNA with four building blocks, remained a complete mystery. Today, the genetic code can be found in tables in any biochemistry textbook (see Tab. 1), including the chemical details of the information transfer from DNA through RNA to the protein (see Infobox 1).
|
Table 1. The genetic code. |
 |
However, it is still worthwhile to take a look back, because this shows the brilliance, ingenuity, intuition, and luck of the many researchers involved in solving this puzzle. The fact that they occasionally lost their way makes this retrospective even more appealing. We will try to reconstruct the astute insights and wild speculation and delight in the fact that we can stand on the shoulders of these giants and look into the distance.
2. George Gamow’s Diamond Code
Theoretical Physics
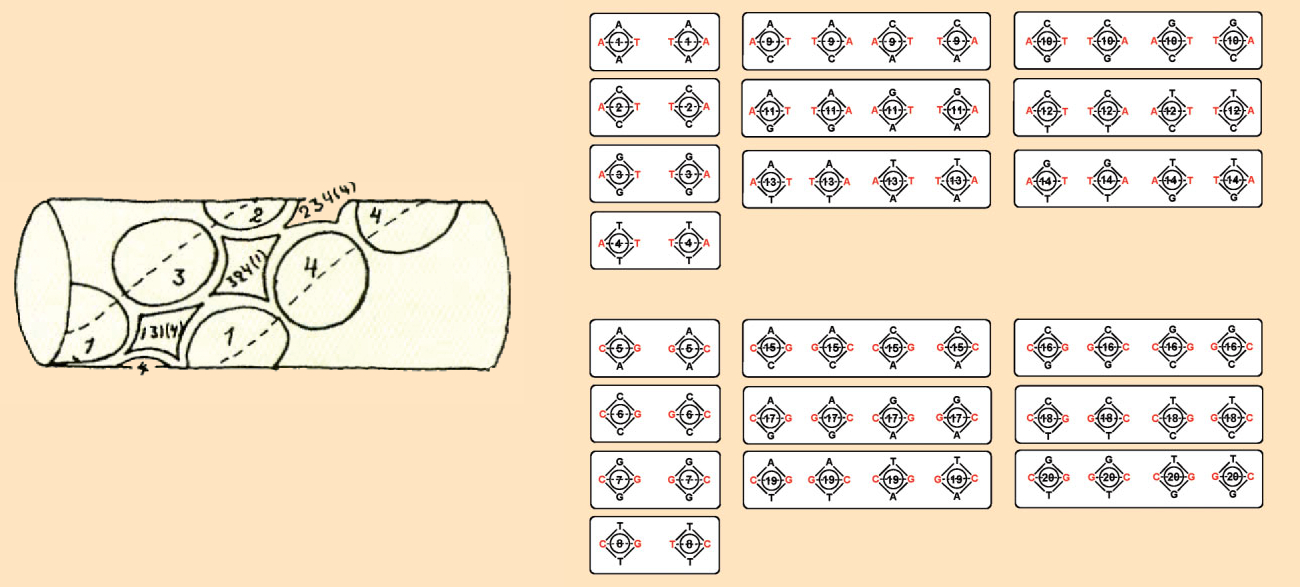
The first attempt to unlock the genetic code was presented by George Gamow. As a theoretical physicist, he analyzed the problem fully decoupled from biochemical constraints and proposed the amazingly simple diamond code (see Fig. 2).
 |
|
Figure 2. George Gamow’s diamond code. Right: The 64 different diamonds can be sorted into exactly 20 subgroups that each encode one amino acid (number in circles). |
Because of the similar distances between two neighboring nucleobases in DNA (340 nm) and two neighboring amino acids in a protein (370 nm), George Gamow assumed that protein synthesis occurs directly on the DNA. According to his idea, the various amino acids and their side chains bind in specific “cavities” formed by four bases in the DNA strand. In his original illustration, one can see the diamond-shaped space that gave the code its name [7] (see Fig. 2, left).
With four different bases at the corners of a diamond, it is possible to have 64 combinations in which the left and right bases always form a Watson-Crick pair (in Fig. 2, in red on the right), AT or GC. According to Gamow, the binding of the amino acid side chain is not affected if the two bases in the Watson-Crick pair switch sides, or if the upper and lower bases are swapped. This allows the 64 different diamonds to be classified into 20 subgroups that each code for one amino acid (see Fig 2, right). This was the origin of the “magic twenty”.
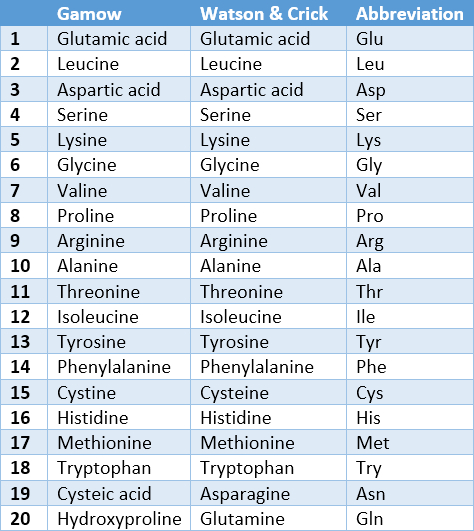
Gamow took a list with the 25 most common amino acids and, because his code only allowed for 20, simply included only the first 20 (see Tab. 2). Neither facts nor “magic” were involved: Gamow’s mathematical analysis was the only source for the number 20. This code was later called the diamond code.
|
Table 2. Gamow’s and Watson and Crick’s “Magic Twenty”. |
 |
Gamow’s proposal had some weight, as he was internationally known and had contributed to the development of the Big Bang Theory, among others [8]. Gamow was a charming and endearing contemporary with a great, if sometimes very quirky, sense of humor. In the publication “The Origin of Chemical Elements”, written with his doctoral student Ralph Alpher, he wanted to make his completely uninvolved friend Hans Bethe (Nobel Prize for Physics in 1967) a co-author only to have the list of authors read Alpher, Bethe, Gamow. This α-β-γ paper introduced the Big Bang Theory for the first time.
Physics and Biology
Watson and Crick had not yet thought about the genetic code. Gamow was the first to get them to do so—primarily because they did not think much of the diamond code. As a biologist, it was clear to Watson that the DNA in the nucleus could not directly act as the template for protein synthesis, because protein synthesis happens outside of the nucleus.
Physicist Crick did not believe that DNA could be read independently of its direction, i.e., that a single DNA sequence could code both Thr-Pro-Lys-Ala and Ala-Lys-Pro-Thr. Both had serious doubts about the amino acids listed by Gamow (see Tab. 2) and Watson even mentioned “embarrassing mistakes” [9].
The Magic Twenty and the RNA Tie Club
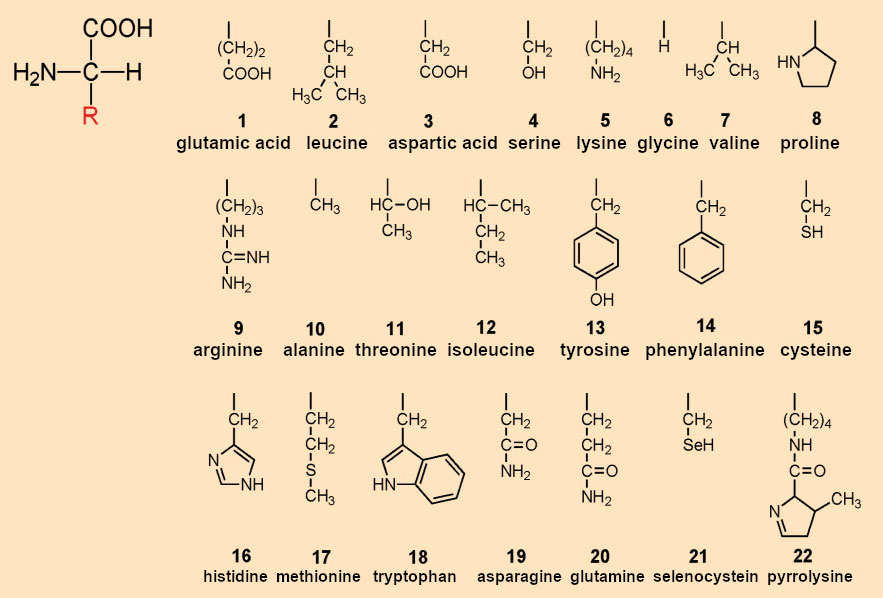
Watson and Crick promptly sat down and wrote down “their” amino acids. Just like Gamow, they came up with 20. The “magic twenty” was born. It must be emphasized that there is absolutely no biochemical basis for either exactly the number 20 or for precisely these 20 amino acids. It is truly a wondrous mixture of intuition and luck that all life forms do indeed synthesize their proteins from these, and that Watson and Crick did indeed write down the “magic twenty” as they still stand today in the spring of 1954 (see Tab. 2 and Fig. 3).
 |
|
Figure 3. The proteinogenic amino acids. |
The lively Gamow corresponded with all of the important scientists working in this area at the time and accepted their biochemical arguments that it is not the DNA in the nucleus, but a single-stranded RNA copy that translates the genetic information during protein synthesis outside of the nucleus. This RNA is called messenger RNA (mRNA). RNA differs chemically from DNA in two ways: The desoxyribose is replaced by ribose and the nucleobase thymine is replaced by uracil. Because of the complete concordance between T and U, decryption of the genetic code is not changed in the least.
Gamow founded the “RNA Tie Club”, whose sole goal was to decipher the genetic code. Each club member received a tie with a green-yellow double helix and an amino acid from Watson and Crick’s list (see Fig. 4). Although the RNA Tie Club never held an official meeting, it fostered the rapid exchange of highly speculative ideas, if only within the exclusive club.
 |
|
Figure 4. Four members of the RNA Tie Club. From left to right: F. Crick (tyrosine), A. Rich (arginine), L. Orgel (threonine), and J. Watson (proline). |
3. The End of the Diamond Code
Crick’s first “Note for the RNA Tie Club”, sent in the spring of 1955, packed a punch and is maybe the most influential unpublished work of modern natural science [10]. In this note, Crick introduces a concept for protein synthesis that Sydney Bremmer (see List of Scientists below) proposed calling the Adaptor Hypothesis. According to this proposal, each amino acid has a special adaptor that is used to bring the amino acid to a template where protein synthesis takes place. This wild speculation proved to be right, and the adaptors are now known as transfer RNAs (tRNA).
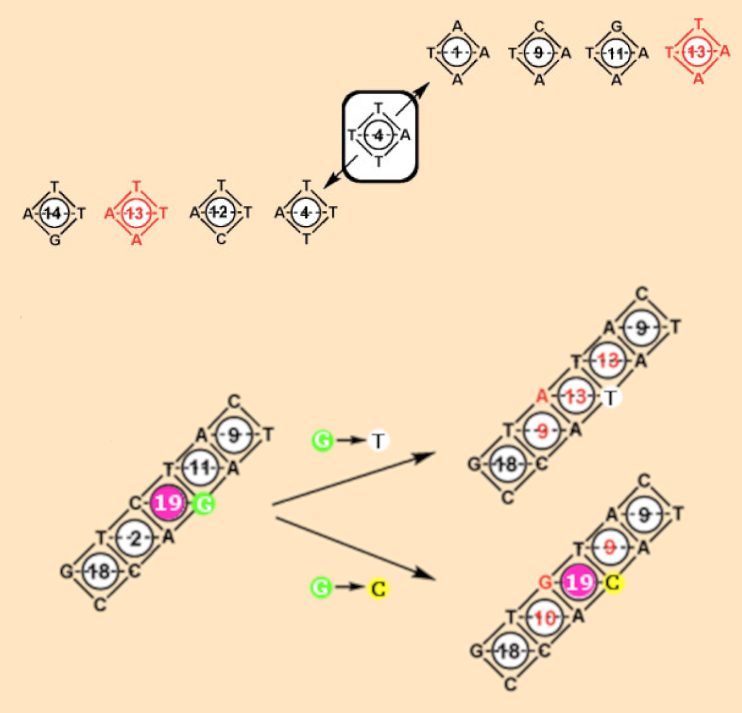
Crick first discussed the diamond code and refuted it in several ways. The diamond code is overlapping, meaning that each base does not determine the selection of only a single amino acid. Crick discovered that in the diamond code, a specific amino acid cannot be implied by two amino acid pairs. Let us assume that tyrosine is amino acid #4 in Figure 5. Like in a game of dominoes, only four different diamonds can be set out on each side of #4 (see Fig. 5, top and compare Fig. 2, right). These include only one identical pair: amino acid #13. With the diamond code, the two experimentally observed partial amino acid sequences Ser-Tyr-Ser and Leu-Tyr-Leu cannot be coded.
 |
|
Figure 5. The end of Gamow’s diamond code. Top: An amino acid cannot be enclosed by two identical pairs of amino acids. Bottom: It is not possible to exchange only one amino acid by changing a base. |
The diamond code was also unable to explain another important finding. Insulin from sheep differs from rat insulin by only a single amino acid (sheep = glycine; rat = serine). This is not explainable by the diamond code, because in the overlapping code, the exchange of one base always leads to the exchange of two or three amino acids (see Fig. 5, bottom).
Crick’s analysis went even deeper because he doubted that an overlapping code could represent the full diversity of the protein amino acid sequences known at that time. Sydney Brenner picked up this idea and counted by hand (!) the amino acid triplets (tripeptides) found in the 24 proteins known at the time. He found 70 different amino acid triplets. However, an overlapping code can only code a maximum of 64 triplets. This was the end for all overlapping codes [11].
Other scientists, including Feynman, Teller, and Gamow, speculated about other codes because each of them wanted to be the first to decipher the “code of life”. These efforts proved to be in vain, as all of the codes they devised proved to be wrong for a wide variety of reasons. But then, over 60 years ago, Crick, Griffith, and Orgel proposed a code of such great simplicity and elegance that it simply could not be wrong [12]! The three authors sent the basis of this publication as “Note for the RNA Tie Club” in May of 1956. We will try to reproduce their lines of reasoning.
4. Codes without Commas
Using two of the four possible bases (A, C, G, U) is not enough to code 20 amino acids, because they can encode only 42 = 16 amino acids; at least three bases with 43 = 64 combinations are required. Experiments with artificially mutated viruses proved that amino acids are indeed encoded by triplets of nucleobases (called codons) in DNA.
In addition, the starting point of the reading frame must also be defined to indicate at which base the reading begins. The following “triplet” sentence illustrates this with our alphabet:
…APTHECOWSAWREDANDRANTOOFARRW…
Reading a statement made of three-letter words is hardly possible, because where do we start? However, properly placed commas make it into child’s play:
…AP,THE,COW,SAW,RED,AND,RAN,TOO,FAR,RW…
“How do we read the code if the commas are erased?”, asked Crick, and discussed two possible solutions:
- The starting point of the reading frame must be chemically marked in some way, or
- The codon sequence can only be read in one unambiguous way.
The first possibility was discarded as unlikely because how would a starting point be chemically defined in a long polymer chain? Today we know that the starting point is indeed marked on the DNA. The enzyme polymerase II binds to a characteristic segment of the sequence (TATA box), and the copying of DNA to mRNA begins 16 positions later.
The second alternative seemed more likely at the time. Let’s take another look at our absurd sentence:
- sensible triplets: …APTHECOWSAWREDANDRANTOOFARRW…
- nonsense triplets: …APTHECOWSAWREDANDRANTOOFARRW…
- nonsense triplets: …APTHECOWSAWREDANDRANTOOFARRW…
This sequence of letters can only be read in one way as a “triplet text” (top), a shift in the reading frame by one or two letters leads to nonsense “texts”. If we apply this to the genetic code, only a single sensible codon sequence should be readable from any RNA segment:
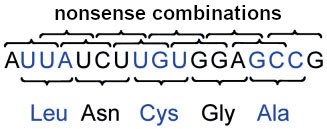
The amino acids can only be read sensibly when starting at the UUA triplet. Each shift in the reading frame leads to nonsense triplets, i.e., in this example, UAU and AUC or AUC and UUG would be unable to encode an amino acid. Such codes can actually be compiled (see Fig. 6).
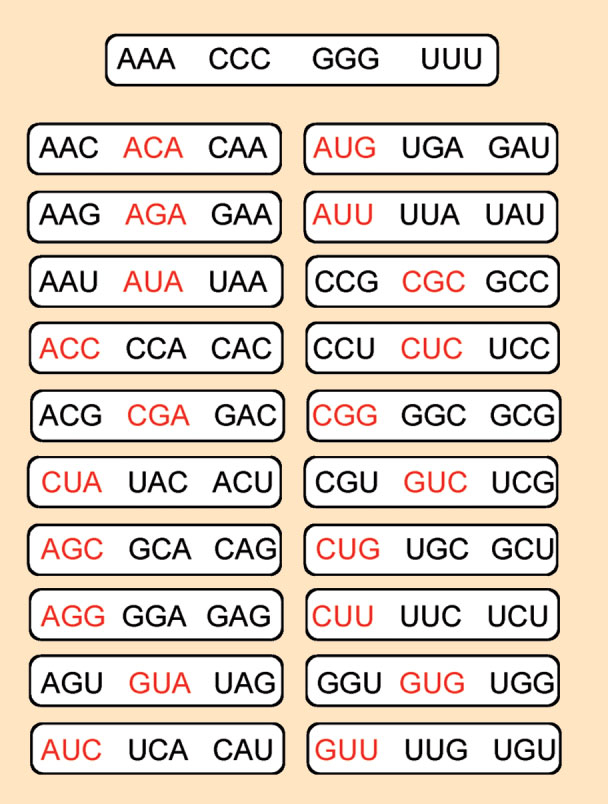 |
|
Figure 6. The code without commas developed by Crick et al. in 1957. Only certain triplets are “allowed”. |
Of the 64 possible combinations of the four RNA bases (ACGU), the triplets with three identical bases; AAA, CCC, GGG, and UUU; must be excluded. The proof: in doubling such triplets, such as in AAAAAA, the codon AAA could be read starting from several starting positions. This is not permissible in a comma-free code.
The remaining 60 combinations can be arranged into groups of three in which the three bases can be cyclically exchanged, e.g., AGU, GUA, and UAG (see Fig. 6). Within each group of three, only one combination can be sensible, the other two must have no meaning when read. Proof: if we link two AGU triplets to AGUAGU, then GUA and UAG must not have any meaning.
With these rules in place, how many amino acids can be encoded with four nucleobases? Exactly 20! The comma-free code devised by Crick, Griffith, and Orgel leaves nothing to be desired because it can encode exactly the “magic twenty” amino acids and the genetic information can be read out without error because the code automatically finds the starting point.
5. The End of the Code without Commas
Despite its impressive elegance, the authors were cautious: “… The arguments and assumptions which we have had to employ to deduce this code are too precarious for us to feel much confidence in it on purely theoretical grounds. We put it forward because it gives the magic number—20—in a neat manner and from reasonable physical postulates. … Some direct experimental support is therefore required before our idea can be regarded as anything more than a tentative hypothesis” [12].
Regardless of these words of caution, the comma-free code took science by storm because of its intellectual elegance alone. The following years were dominated by the code without commas, all thinking was based on it, and experiments were always looking for agreement with the code.
Then came a surprise: A nobody—not a member of the exclusive RNA Tie Club—succeeded in providing the required experimental proof of the code without commas: Marshall W. Nirenberg and his German postdoctoral researcher J. Heinrich Matthaei.
In Part Two, read about how the experimental verification of the code without commas was accomplished and why nature does not use this brilliant code, preferring to use less elegant routes of its own.
List of Scientists
 |
Sydney Brenner (1927, Germiston, South Africa – 2019, Singapore) (Photo: OIST, wikimedia commons, CC BY 2.0) |
 |
Francis Harry Compton Crick (1916, Northamptonshire, England, UK – 2004, San Diego, CA, USA) (Photo: Marc Lieberman, wikimedia commons, CC BY 2.5) |
 |
Rosalind Elsie Franklin (1920, London, UK – 1958, London, UK) (Photo: MRC Laboratory of Molecular Biology, wikimedia commons, CC BY-SA 4.0) |
 |
George Gamow (1904, Russia – 1968, Boulder, CO, USA) |
.png) |
John Stanley Griffith (1928, UK – 1972, London, UK) |
 |
J. Heinrich Matthaei (1929, Bonn, Germany) |
.jpg) |
Marshall W. Nirenberg (1927, New York, USA – 2010, New York, USA) |
 |
Leslie Eleazer Orgel (1927, London, UK – 2007, San Diego, CA, USA) |
 |
James Dewey Watson (*1928, Chicago, IL, USA) |
 |
Maurice Hugh Frederick Wilkins (1916, Pongaroa, New Zealand – 2004, London, UK) |
References
[1] H. F. Judson, The Eighth Day of Creation: The Makers of the Revolution in Biology, Cold Spring Harbor Laboratory Press, Woodbury, 1996. ISBN: 978-087969478-4
[2] B. Hayes, The Invention of the Genetic Code, Amer. Sci. 1998, 86, 8.
[3] J. Maynard-Smith, Too Good to Be True, Nature 1999, 400, 223. https://doi.org/10.1038/22238
[4] J. D. Watson, The Double Helix, Phoenix, UK, 2010. ISBN: 978-0753828434
[5] J. D. Watson, F. H. C. Crick, Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid, Nature 1953, 171, 737–738. https://doi.org/10.1038/171737a0
[6] J. D. Watson, F. H. C. Crick, Genetical Implications of the Structure of Deoxyribonucleic Acid, Nature 1953, 171, 964–967. https://doi.org/10.1038/171964b0
[7] G. Gamow, Possible Relation between Deoxyribonucleic Acid and Protein Structures, Nature 1954, 173, 318. https://doi.org/10.1038/173318a0
[8] R. A. Alpher, H. Bethe, G. Gamow, The Origin of Chemical Elements, Phys. Rev. 1948, 73, 803. https://doi.org/10.1103/PhysRev.73.803
[9] J. D. Watson, A Passion for DNA: Genes, Genomes, and Society, Cold Spring Harbor Laboratory Press, 2000. ISBN: 978-087969581-1
[10] F. H. C. Crick, On Degenerate Templates and the Adaptor Hypothesis: A Note for the RNA Tie Club, 1955.
[11] S. Brenner, On The Impossibility Of All Overlapping Triplet Codes In Information Transfer From Nucleic Acid To Proteins, Proc. Natl. Acad. Sci. USA 1957, 43, 687–694. https://doi.org/10.1073/pnas.43.8.687
[12] F. H. C. Crick, J. S. Griffith, L. E. Orgel, Codes Without Commas, Proc. Natl. Acad. Sci. USA 1957, 43, 416–421. https://doi.org/10.1073/pnas.43.5.416
The article has been published in German as:
- Die schönste falsche Theorie der Biochemie. Aus 4 mach’ 20, oder 21, oder 22, oder ….,
Klaus Roth,
Chem. unserer Zeit 2007, 41, 448–458.
https://doi.org/10.1002/ciuz.200700446
and was translated by Caroll Pohl-Ferry.
Deciphering the Genetic Code: The Most Beautiful False Theory in Biochemistry – Part 2
How the experimental verification of the genetic code was accomplished
Deciphering the Genetic Code: The Most Beautiful False Theory in Biochemistry – Part 3
Does Nature use only 20 amino acids?
See similar articles by Klaus Roth published on ChemistryViews.org
![]()



